Qu'est-ce que l'imagerie numérique?
![]() Introduction à la notion de lumière
Introduction à la notion de lumière
![]() Le codage de la couleur
Le codage de la couleur
![]() Infographie : le codage des images
Infographie : le codage des images
![]() Images bitmap et vectorielles
Images bitmap et vectorielles
![]() Format de fichier graphique
Format de fichier graphique
![]() Le format BMP
Le format BMP
![]() Le format GIF
Le format GIF
![]() Le format PCX
Le format PCX
![]() Le format PNG
Le format PNG
![]() Le format TIF
Le format TIF
![]() La compression des données
La compression des données
![]() La compression des images numériques
La compression des images numériques
![]() Le traitement d'images
Le traitement d'images
![]() Les filtres de traitement d'images
Les filtres de traitement d'images
 Introduction à la notion de lumière
Introduction à la notion de lumière
Qu'est-ce que la lumière?
La lumière est une forme d'énergie issue de deux composantes:
- une onde électromagnétique ondulatoire
- un aspect corpusculaire (les photons)
La lumière émise par le soleil se déplace à une vitesse d'environ 300 000 km/s, à une fréquence d'environ 600 000 GHz.
Notion de couleur
La couleur de la lumière est caractérisée par sa fréquence, elle-même conditionnée par la longueur d'onde et la célérité de l'onde. On caractérise généralement la longueur d'onde d'un phénomène oscillatoire par la relation:
λ = CT où :
- λ désigne la longueur d'onde
- C désigne la célérité de l'onde
- T désigne la période de l'onde (en secondes)
On appelle rayonnement monochromatique un rayonnement comportant une seule longueur d'onde et rayonnement polychromatique un rayonnement qui en contient plusieurs. L'ensemble des longueurs d'ondes composant un rayonnement polychromatique (et leurs intensités lumineuses respectives) est appelé spectre.
Toutefois l'oeil humain n'est pas capable de discerner les différentes composantes d'un rayonnement et ne perçoit que la résultante, fonction des différentes longueur d'ondes qui le composent et de leur intensité lumineuse respective.
Il est possible de décomposer les couleurs spectrales à l'aide d'un prisme en cristal.
L'oeil humain est capable de voir des rayonnements dont la longueur d'onde est comprise entre 380 et 780 nanomètres. En dessous de 380 nm se trouvent des rayonnements tels que les ultraviolets, tandis que les rayons infrarouges ont une longueur d'onde au-dessus de 780 nm. L'ensemble des longueurs d'ondes visibles par l'oeil humain est appelé « spectre visible » :
![]()
Il est possible de décomposer les couleurs spectrales à l'aide d'un prisme en cristal.
Le fonctionnement de l'oeil humain
Grâce à la cornée (l'enveloppe translucide de l'oeil) et de l'iris (qui en se fermant permet de doser la quantité de lumière), une image se forme sur la rétine. Celle-ci est composée de petits bâtonnets (en anglais rods) et de cônes (en anglais cones).
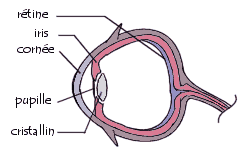
Les bâtonnets, formés d'une pigmentation appelée rhodopsine et situés en périphérie de la retine, permettent de percevoir la luminosité et le mouvement (vision scotopique), tandis que les cônes, situés dans un zone appelée fovéa, permettent de différencier les couleurs (vision photopique). Il existe en réalité trois sortes de cônes:
- une sorte pour le rouge (570 nm), appelés erythrolabes
- une sorte pour le vert (535 nm), appelés chlorolabes
- une sorte pour le bleu (445 nm), appelés cyanolabes
Ainsi, lorsqu'un type de cône fait défaut, la perception des couleurs est imparfaite, on parle alors de daltonisme (ou dichromasie. On distingue généralement les personnes présentant cette anomalie selon le type de cône défectueux :
- Les protanopes sont insensibles au rouge
- Les deutéranopes sont insensibles au vert
- Les trinatopes sont insensibles au bleu
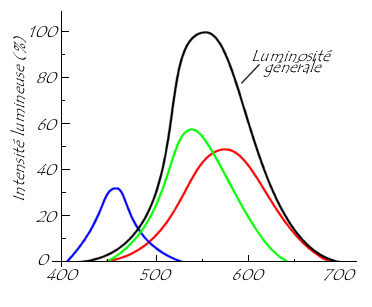
D'autre part il est à noter que la sensibilité de l'oeil humain aux intensités lumineuses relatives aux trois couleurs primaire est inégale :
Synthèse additive et soustractive
Il existe deux types de synthèse de couleur:
 La synthèse additive est le fruit de l'ajout de composantes de la lumière. Les composantes de la lumière sont directement ajoutée à l'émission, c'est le cas pour les moniteurs ou les télévisions en couleur. Lorsque l'on ajoute les trois composantes Rouge, vert, bleu (RVB), on obtient du blanc. L'absence de composante donne du noir. Les couleurs secondaires sont le cyan, le magenta et le jaune car :
La synthèse additive est le fruit de l'ajout de composantes de la lumière. Les composantes de la lumière sont directement ajoutée à l'émission, c'est le cas pour les moniteurs ou les télévisions en couleur. Lorsque l'on ajoute les trois composantes Rouge, vert, bleu (RVB), on obtient du blanc. L'absence de composante donne du noir. Les couleurs secondaires sont le cyan, le magenta et le jaune car :
Le vert combiné au bleu donne du cyan
Le bleu combiné au rouge donne du magenta
Le vert combiné au rouge donne du jaune
 La synthèse soustractive permet de restituer une couleur par soustraction, à partir d'une source de lumière blanche, avec des filtres correspondant aux couleurs complémentaires : jaune, magenta, et cyan. L'ajout de ces trois couleurs donne du noir et leur absence produit du blanc.
La synthèse soustractive permet de restituer une couleur par soustraction, à partir d'une source de lumière blanche, avec des filtres correspondant aux couleurs complémentaires : jaune, magenta, et cyan. L'ajout de ces trois couleurs donne du noir et leur absence produit du blanc.
Les composantes de la lumière sont ajoutées après réflection sur un objet, ou plus exactement sont absorbées par la matière. Ce procédé est utilisé en photographie et pour l'impression des couleurs. Les couleurs secondaires sont le bleu, le rouge et le vert car :
Le magenta (couleur primaire) combiné avec le cyan (couleur primaire) donne du bleu
Le magenta (couleur primaire) combiné avec le jaune (couleur primaire) donne du rouge
Le cyan (couleur primaire) combiné avec le jaune (couleur primaire) donne du vert
Deux couleurs sont dites « complémentaires » si leur association donne du blanc en synthèse additive, ou du noir en synthèse soustractive.
Le codage de la couleur
Les représentations de la couleur
Afin de pouvoir manipuler correctement des couleurs et échanger des informations colorimétriques il est nécessaire de disposer de moyens permettant de les catégoriser et de les choisir. Ainsi, il n'est pas rare d'avoir à choisir la couleur d'un produit avant même que celui-ci ne soit fabriqué. Dans ce cas, une palette de couleurs est présentée, dans laquelle la couleur convenant le mieux au besoin est choisie. La plupart du temps le produit (véhicule, bâtiment, etc.) possède une couleur qui correspond à celle choisie.
En informatique, de la même façon, il est essentiel de disposer d'un moyen de choisir une couleur parmi toutes celles utilisables. Or la gamme de couleurs possibles est très vaste et la chaîne de traitement de l'image passe par différents périphériques : par exemple un numériseur (scanner), puis un logiciel de retouche d'image et enfin une imprimante. Il est donc nécessaire de pouvoir représenter de façon fiable la couleur afin de s'assurer de la cohérence entre ces différents périphériques.
On appelle ainsi «espace de couleurs» la représentation mathématique d'un ensemble de couleurs. Il en existe plusieurs, parmi lesquels les plus connus sont :
- Le codage RGB (Rouge, Vert, Bleu, en anglais RGB, Red, Green, Blue).
- Le codage TSL (Teinte, Saturation, Luminance, en anglais HSL, Hue, Saturation, Luminance).
- Le codage CMYK.
- Le codage CIE.
- Le codage YUV.
- Le codage YIQ.
Le spectre de couleurs qu'un périphérique d'affichage permet d'afficher est appelé gamut ou espace colorimétrique. Les couleurs n'appartenant pas au gamut sont appelées couleurs hors-gamme.
Le codage RGB
Le codage RGB, mis au point en 1931 par la Commission Internationale de l'Eclairage (CIE) consiste à représenter l'espace des couleurs à partir de trois rayonnements monochromatiques de couleurs :
- rouge (de longueur d'onde égale à 700,0 nm),
- vert (de longueur d'onde égale à 546,1 nm),
- bleu (de longueur d'onde égale à 435,8 nm).
Cet espace de couleur correspond à la façon dont les couleurs sont généralement codées informatiquement, ou plus exactement à la manière dont les tubes cathodiques des écrans d'ordinateurs représentent les couleurs.
Ainsi, le modèle RGB propose de coder sur un octet chaque composante de couleur, ce qui correspond à 256 intensités de rouge (28), 256 intensités de vert et 256 intensités de bleu, soient 16777216 possibilités théoriques de couleurs différentes, c'est-à-dire plus que ne peut en discerner l'oeil humain (environ 2 millions). Toutefois, cette valeur n'est que théorique car elle dépend fortement du matériel d'affichage utilisé.
Etant donné que le codage RGB repose sur trois composantes proposant la même gamme de valeur, on le représente généralement graphiquement par un cube dont chacun des axes correspond à une couleur primaire :
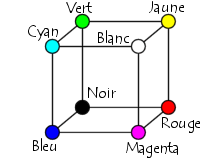
Le codage HSL
Le modèle HSL (Hue, Saturation, Luminance, ou en français TSL), s'appuyant sur les travaux du peintre Albert H.Munsell (qui créa l'Atlas de Munsell), est un modèle de représentation dit "naturel", c'est-à-dire proche de la perception physiologique de la couleur par l'oeil humain. En effet, le modèle RGB aussi adapté soit-il pour la représentation informatique de la couleur ou bien l'affichage sur les périphériques de sortie, ne permet pas de sélectionner facilement une couleur. En effet, le réglage de la couleur en RGB dans les outils informatiques se fait généralement à l'aide de trois glisseurs ou bien de trois cases avec les valeurs relatives de chacune des composantes primaires, or l'éclaircissement d'une couleur demande d'augmenter proportionnellement les valeurs respectives de chacune des composantes. Ainsi le modèle HSL a-t-il été mis au point afin de pallier cette lacune du modèle RGB.
Le modèle HSL consiste à décomposer la couleur selon des critères physiologiques :
- la teinte (en anglais Hue), correspondant à la perception de la couleur (T-shirt mauve ou orange),
- la saturation, décrivant la pureté de la couleur, c'est-à-dire son caractère vif ou terne (T-shirt neuf ou délavé),
- la luminance, indiquant la quantité de lumière de la couleur, c'est-à-dire son aspect clair ou sombre (T-shirt au soleil ou à l'ombre).
Voici une représentation graphique du modèle HSL, dans lequel la teinte est représentée par un cercle chromatique et la luminance et la saturation par deux axes :

Le modèle HSL a été mis au point dans le but de permettre un choix interactif rapide d'une couleur, pour autant il n'est pas adapté à une description quantitative d'une couleur.
Il existe d'autres modèles naturels de représentation proches du modèle HSL :
- HSB : Hue, Saturation, Brightness soit Teinte, Saturation, Brillance en français. La brillance décrit la perception de la lumière émise par une surface.
- HSV : Hue, Saturation, Value soit Teinte, Saturation, Valeur en français
- HSI : Hue, Saturation, Intensity soit Teinte, Saturation, Intensité en français
- HCI : Hue, Chrominance, Intensity soit Teinte, Chrominance, Intensité
Le codage CMY
Le codage CMY (Cyan, Magenta, Yellow, ou Cyan, Magenta, Jaune en français, soit CMJ) est à la synthèse soustractive, ce que le codage RGB est à la synthèse additive. Ce modèle consiste à décomposer une couleur en valeurs de Cyan, de Magenta et de Jaune.
L'absence de ces trois composantes donne du blanc tandis que leur ajout donne du noir. Toutefois, le noir obtenu par l'ajout des trois couleurs Cyan, Magenta et Jaune n'étant que partiellement noir en pratique (et coûtant cher), les imprimeurs rajoutent une composante d'encre noire que l'on appelle noir pur. On parle alors de quadrichromie, ou modèle CMYK (Cyan, Magenta, Jaune, Noir pur, ou en français CMJN).
Le codage CIE
Les couleurs peuvent être perçues différemment selon les individus et peuvent être affichées différemment selon les périphériques d'affichage. La Commission Internationale de l'Eclairage (CIE) a donc défini des standards permettant de définir une couleur indépendamment des périphériques utilisés. A cette fin, la CIE a défini des critères basés sur la perception de la couleur par l'oeil humain, grâce à un triple stimulus.
En 1931 la CIE a élaboré le système colorimétrique xyY représentant les couleurs selon leur chromaticité (axes x et y) et leur luminance (axe Y). Le diagramme de chromaticité (ou diagramme chromatique), issu d'une transformation mathématique représente sur la périphérie les couleurs pures, c'est-à-dire les rayonnements monochromatiques correspondant aux couleurs du spectre (couleurs de l'arc en ciel), repérées par leur longueur d'onde. La ligne fermant le diagramme (donc fermant les deux extrémités du spectre visible) se nomme la droite des pourpres, car elle correspond à la couleur pourpre, composée des deux rayonnements monochromatiques bleu (420 nm) et rouge (680 nm) :
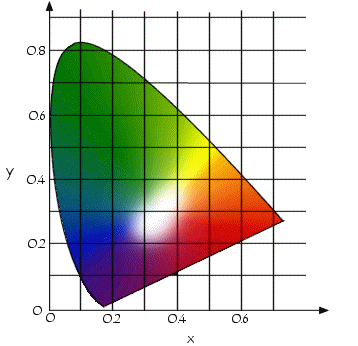
On représente généralement le gamut d'un dispositif d'affichage en traçant dans le diagramme chromatique un polygone renfermant toutes les couleurs qu'il est capable de produire.
Toutefois ce mode de représentation purement mathématique ne tient pas compte des facteurs physiologiques de perception de la couleur par l'oeil humain, ce qui résulte en un diagramme de chromaticité laissant par exemple une place beaucoup trop large aux couleurs vertes.
En 1960 la CIE mit au point le modèle Lu*v*.
Enfin en 1976, afin de remédier aux lacunes du modèle xyY, la CIE développe le modèle colorimétrique La*b* (aussi connu sous le nom de CIELab), dans lequel une couleur est repérée par trois valeurs :
- L, la luminance, exprimée en pourcentage (0 pour le noir à 100 pour le blanc)
- a et b deux gammes de couleur allant respectivement du vert au rouge et du bleu au jaune avec des valeurs allant de -120 à +120.
Le mode Lab couvre ainsi l'intégralité du spectre visible par l'oeil humain et le représente de manière uniforme. Il permet donc de décrire l'ensemble des couleurs visibles indépendamment de toute technologie graphique. De cette façon il comprend la totalité des couleurs RGB et CMYK, c'est la raison pour laquelle des logiciels tels que PhotoShop utilisent ce mode pour passer d'un modèle de représentation à un autre.
Il s'agit d'un mode très utilisé dans l'industrie, mais peu retenu dans la plupart des logiciels étant donné qu'il est difficile à manipuler.
Les modèles de la CIE ne sont pas intuitifs, toutefois le fait de les utiliser garantit qu'une couleur créée selon ces modèles sera vue de la même façon par tous !
Le codage YUV
Le modèle YUV (appelé aussi CCIR 601) est un modèle de représentation de la couleur dédié à la vidéo analogique. Il s'agit du format utilisé dans les standards PAL (Phase Alternation Line) et SECAM (Séquentiel Couleur avec Mémoire). Le paramètre Y représente la luminance (c'est-à-dire l'information en noir et blanc), tandis que U et V permettent de représenter la chrominance, c'est-à-dire l'information sur la couleur. Ce modèle a été mis au point afin de permettre de transmettre des informations colorées aux téléviseurs couleurs, tout en s'assurant que les téléviseurs noir et blanc existant continuent d'afficher une image en tons de gris.
Voici les relations liant Y à R, G et B, U à R et à la luminance, et enfin V à B et à la luminance :
- Y = 0.299R + 0.587 G + 0.114 B
- U = -0.147R - 0.289 G + 0.436B = 0.492(B - Y)
- V = 0.615R -0.515G -0.100B = 0.877(R-Y)
Ainsi U est parfois noté Cr et V noté Cb, d'où la notation YCrCb.
Le codage YIQ
Le modèle YIQ est très proche du modèle YUV. Il est notamment utilisé dans le standard vidéo NTSC (utilisé entre autres aux États-Unis et au Japon).
Le paramètre Y représente la luminance. I et Q représentent respectivement l'Interpolation et la Quadrature. Les relations entre ces paramètres et le modèle RGB sont les suivantes :
- Y = 0.299 R + 0.587 G + 0.114 B
- I = 0.596 R - 0.275 G - 0.321 B
- Q = 0.212 R - 0.523 G + 0.311 B
La sélection des couleurs dans un logiciel
La plupart des logiciels graphiques offrent des moyens de sélectionner une couleur de manière interactive. La principale est souvent le nuancier, c'est-à-dire la présentation des couleurs dans un tableau dans lequel elles sont classées par nuances :
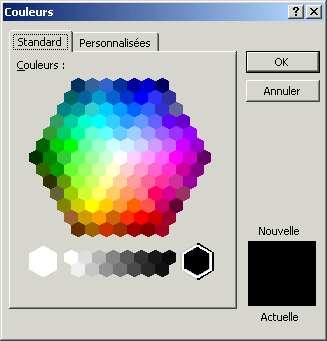
De plus en plus de logiciels intègrent toutefois des outils plus performants permettant de choisir une couleur parmi une vaste gamme. Ainsi, dans le sélectionneur de couleur ci-dessous, la teinte est représentée par un disque chromatique, tandis que la luminance est représentée par un sélecteur vertical donnant les nuances de la couleur allant du noir au blanc.
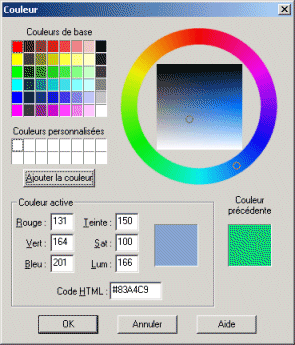
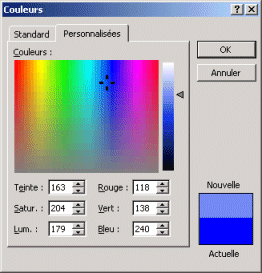
Dans le sélecteur ci-dessous par contre, la teinte est présentée en abscisses du sélecteur de gauche, et la saturation est en ordonnée. Le sélecteur de droite permet de régler la luminosité :
Facteur Gamma
On appelle facteur gamma le critère définissant le caractère non linéaire de l'intensité lumineuse d'un élément.
Ainsi la luminance d'un écran d'ordinateur est non linéaire dans la mesure où :
- l'intensité lumineuse qu'il émet n'est pas linéairement proportionnelle à la tension appliquée, mais correspond à une courbe fonction du gamma de l'écran (généralement compris entre 2,3 et 2,6) :
I ~ Vgamma
- l'intensité lumineuse perçue par l'oeil n'est pas proportionnelle à la quantité de lumière effectivement émise
Afin de remédier à cet effet et obtenir une reproduction satisfaisante de l'intensité lumineuse, il est possible de compenser la luminance en appliquant une transformation appelée «correction gamma».
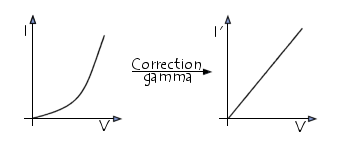
Ainsi à chaque périphérique d'affichage correspond une transformation gamma, pouvant elle-même être adaptée à la perception de l'utilisateur.
La gestion de la couleur
Il est facile de comprendre l'intérêt du respect des couleurs d'une image lors du passage de celle-ci via plusieurs périphériques (chaîne numérique composée par exemple d'un scanner, d'un logiciel de traitement d'image, puis d'une imprimante) afin de s'assurer que l'image en fin de chaîne de traitement possède des couleurs proches de l'image d'origine. On appelle «gestion de la couleur» l'ensemble des opérations nécessaires afin de garantir la bonne conservation des couleurs d'une image.
Afin de pouvoir garantir la cohérence des couleurs il est essentiel d'étalonner (ou calibrer) l'ensemble des matériels de la chaîne numérique. Le calibrage (ou étalonnage) d'un matériel consiste ainsi à décrire dans un fichier, appelé profil ICC (International Color Consortium), l'ensemble des couleurs qu'il est capable d'acquérir ou de produire (il s'agit donc de son gamut) dans un espace de couleur indépendant (par exemple CIE Lab ou CIE XYZ).
Ce profil ICC est intégré dans l'image et véhicule l'ensemble des transformations qu'elle a subi le long de la chaîne de traitement, à la manière d'un carnet de suivi.
Infographie : le codage des images
On appelle infographie le domaine de l'informatique concernant la création et la manipulation des images numériques. L'infographie regroupe de nombreux savoirs, parmi lesquels la représentation des éléments graphiques (texte, image ou vidéo), ainsi que leurs transformations (rotation, translation, zoom, ...) par l'intermédiaire d'algorithmes.
Les technologies d'affichage
L'image s'affiche sur un écran (appelé aussi moniteur), il s'agit d'un périphérique de sortie permettant de fournir une représentation visuelle. Ces informations proviennent de l'ordinateur, mais de façon "indirecte". En effet le processeur n'envoie pas directement les informations au moniteur, mais traite les informations provenant de sa mémoire vive (RAM), puis les envoie à une carte graphique qui est chargée de convertir les informations en impulsions électriques qu'elle envoie au moniteur.
Les moniteurs d'ordinateur sont la plupart du temps des tubes cathodiques, c'est à dire un tube en verre dans lequel un canon à électrons émet des électrons dirigés par un champ magnétique vers un écran sur lequel sont disposés de petits éléments phosphorescents (luminophores) constituant des points (pixels) émettant de la lumière lorsque les électrons viennent les heurter.
La notion de pixel
Une image est constituée d'un ensemble de points appelés pixels (pixel est une abréviation de PICture ELement) Le pixel représente ainsi le plus petit élément constitutif d'une image numérique. L'ensemble de ces pixels est contenu dans un tableau à deux dimensions constituant l'image :

Etant donné que l'écran effectue un balayage de gauche à droite et de haut en bas, on désigne généralement par les coordonnées [0,0] le pixel situé en haut à gauche de l'image, cela signifie que les axes de l'image sont orientés de la façon suivante:
- L'axe X est orienté de gauche à droite.
- L'axe Y est orienté de haut en bas, contrairement aux notation conventionnelles en mathématiques, où l'axe Y est orienté vers le haut.
Définition et résolution
On appelle définition le nombre de points (pixel) constituant l'image, c'est-à-dire sa « dimension informatique » (le nombre de colonnes de l'image que multiplie son nombre de lignes). Une image possédant 640 pixels en largeur et 480 en hauteur aura une définition de 640 pixels par 480, notée 640x480.
La résolution, terme souvent confondu avec la "définition", détermine par contre le nombre de points par unité de surface, exprimé en points par pouce (PPP, en anglais DPI pour Dots Per Inch); un pouce représentant 2.54 cm. La résolution permet ainsi d'établir le rapport entre le nombre de pixels d'une image et la taille réelle de sa représentation sur un support physique. Une résolution de 300 dpi signifie donc 300 colonnes et 300 rangées de pixels sur un pouce carré ce qui donne donc 90000 pixels sur un pouce carré. La résolution de référence de 72 dpi nous donne un pixel de 1"/72 (un pouce divisé par 72) soit 0.353mm, correspondant à un point pica (unité typographique anglo saxonne).
Le codage de la couleur
Une image est donc représentée par un tableau à deux dimensions dont chaque case est un pixel. Pour représenter informatiquement une image, il suffit donc de créer un tableau de pixels dont chaque case contient une valeur. La valeur stockée dans une case est codée sur un certain nombre de bits déterminant la couleur ou l'intensité du pixel, on l'appelle profondeur de codage (parfois profondeur de couleur). Il existe plusieurs standards de codage de la profondeur :
- bitmap noir et blanc: en stockant un bit dans chaque case, il est possible de définir deux couleurs (noir ou blanc).
- bitmap 16 couleurs ou 16 niveaux de gris: en stockant 4 bits dans chaque case, il est possible de définir 24 possibilités d'intensités pour chaque pixel, c'est-à-dire 16 dégradés de gris allant du noir au blanc ou bien 16 couleurs différentes.
- bitmap 256 couleurs ou 256 niveaux de gris: en stockant un octet dans chaque case, il est possible de définir 28 intensités de pixels, c'est-à-dire 256 dégradés de gris allant du noir au blanc ou bien 256 couleurs différentes.
- palette de couleurs (colormap): grâce à cette méthode, il est possible de définir une palette, ou table des couleurs, contenant l'ensemble des couleurs pouvant être contenues dans l'image, à chacune desquelles est associé un indice. Le nombre de bits réservé au codage de chaque indice de la palette détermine le nombre de couleurs pouvant être utilisées. Ainsi en codant les indices sur 8 bits il est possible de définir 256 couleurs utilisables, c'est-à-dire que chaque case du tableau à deux dimensions représentant l'image va contenir un nombre indiquant l'indice de la couleur à utiliser. On appelle ainsi image en couleurs indexées une image dont les couleurs sont codées selon cette technique.
- « Couleurs vraies » (True color) ou « couleurs réelles » : cette représentation permet de représenter une image en définissant chacune des composantes (RGB, pour rouge, vert et bleu). Chaque pixel est représenté par un entier comportant les trois composantes, chacune codée sur un octet, c'est-à-dire au total 24 bits (16 millions de couleurs). Il est possible de rajouter une quatrième composante permettant d'ajouter une information de transparence ou de texture, chaque pixel est alors codé sur 32 bits.
Poids d'une image
Pour connaître le poids (en octets) d'une image, il est nécessaire de compter le nombre de pixels que contient l'image, cela revient à calculer le nombre de cases du tableau, soit la hauteur de celui-ci que multiplie sa largeur. Le poids de l'image est alors égal à son nombre de pixels que multiplie le poids de chacun de ces éléments.
Voici le calcul pour une image 640x480 en True color :
- Nombre de pixels :
640 x 480 = 307200
24 bits / 8 = 3 octets
- Le poids de l'image est ainsi égal à :
307200 x 3 = 921600 octets 921600 / 1024 = 900 Ko
(Pour connaître la taille en Ko il suffit de diviser par 1024).
Voici quelques exemples (en considérant que l'image n'est pas compressée) :
| Définition de l'image | Noir et blanc (1 bit) | 256 couleurs (8 bits) | 65000 couleurs (16 bits) | True color (24 bits) |
|---|---|---|---|---|
| 320x200 | 7.8 Ko | 62.5 Ko | 125 Ko | 187.5 Ko |
| 640x480 | 37.5 Ko | 300 Ko | 600 Ko | 900 Ko |
| 800x600 | 58.6 Ko | 468.7 Ko | 937.5 Ko | 1.4 Mo |
| 1024x768 | 96 Ko | 768 Ko | 1.5 Mo | 2.3 Mo |
Cela met en évidence la quantité de mémoire vidéo que nécessite votre carte graphique en fonction de la définition de l'écran (nombre de points affichés) et du nombre de couleurs. L'exemple montre ainsi qu'il faut une carte ayant au minimum 4 Mo de mémoire vidéo afin d'afficher une résolution de 1024x768 en true color...
La transparence
La transparence est une caractéristique permettant de définir le niveau d'opacité des éléments d'une image, c'est-à-dire la possibilité de voir à travers l'image des éléments graphiques située derrière celle-ci.
Il existe deux modes de transparence :
- La transparence simple s'applique pour une image indexée et consiste à définir parmi la palette de couleurs une des couleurs comme transparente
- La transparence par couche alpha (ou canal alpha, en anglais alpha channel) consiste à rajouter pour chaque pixel de l'image un octet définissant le niveau de transparence (de 0 à 255). Le processus consistant à ajouter une couche transparente à une image est généralement appelée alpha blending.
Images bitmap et vectorielles
On distingue généralement deux grandes catégories d'images:
- les images bitmap (appelées aussi images raster) : il s'agit d'images pixellisées, c'est-à-dire un ensemble de points (pixels) contenus dans un tableau ,chacun de ces points possédant une ou plusieurs valeurs décrivant sa couleur.
- les images vectorielles: les images vectorielles sont des représentations d'entités géométriques telles qu'un cercle, un rectangle ou un segment. Ceux-ci sont représentés par des formules mathématiques (un rectangle est défini par deux points, un cercle par un centre et un rayon, une courbe par plusieurs points et une équation). C'est le processeur qui sera chargé de "traduire" ces formes en informations interprétables par la carte graphique.
Etant donné qu'une image vectorielle est constituée uniquement d'entités mathématiques, il est possible de lui appliquer facilement des transformations géométriques (zoom, étirement, ...), tandis qu'une image bitmap, faite de pixels, ne pourra subir de telles transformations qu'au prix d'une perte d'information, appelée distorsion. On nomme ainsi pixellisation (en anglais aliasing) l'apparition de pixels dans une image suite à une transformation géométrique (notamment l'agrandissement). De plus, les images vectorielles (appelées cliparts lorsqu'il s'agit d'un objet vectoriel) permettent de définir une image avec très peu d'information, ce qui rend les fichiers très peu volumineux.
En contrepartie, une image vectorielle permet uniquement de représenter des formes simples. S'il est vrai qu'une superposition de divers éléments simples peut donner des résultats très impressionnants, toute image ne peut pas être rendue vectoriellement, c'est notamment le cas des photos réalistes.
|
image vectorielle
|
image bitmap
|
|---|---|
 |
 |
L'image "vectorielle" ci-dessus n'est qu'une représentation de ce à quoi pourrait ressembler une image vectorielle, car la qualité de l'image dépend du matériel utilisé pour la rendre visible à l'oeil. Votre écran permet probablement de voir cette image à une résolution d'au moins 72 pixels au pouce; le même fichier imprimé sur une imprimante donnerait une meilleure qualité d'image car elle serait imprimée à au moins 300 pixels au pouce.
Grâce à la technologie développée par la compagnie Macromedia et son logiciel Macromedia Flash, ou au plugiciel ("plug-in") SVG, le format vectoriel est aujourd'hui utilisable sur Internet.
Format de fichier graphique
Qu'appelle-t-on format de fichier ?
Nous avons vu précédemment la façon suivant laquelle une image était codée pour l'afficher sur un moniteur, toutefois lorsque l'on veut stocker une image dans un fichier ce format n'est pas le plus pratique...
On peut en effet vouloir une image qui prenne moins de place en mémoire, ou bien une image que l'on puisse agrandir sans faire apparaître de pixellisation.
Ainsi, il est possible de stocker l'image dans un fichier avec une structure de donnée décrivant l'image à l'aide d'équation, et qui devra être décodée par le processeur avant que les informations soient envoyées à la carte graphique:
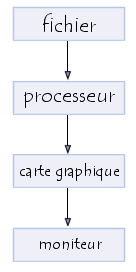
Les types de formats de fichier
Il existe un grand nombre de formats de fichiers. Parmi les formats de fichiers graphiques voici les plus utilisés :
| Format | Compression | Dimensions maximales | Nombre de couleurs maximal |
|---|---|---|---|
| BMP | aucune / RLE | 65 536 x 65 536 | 16 777 216 |
| GIF | LZW | 65 536 x 65 536 | 256 |
| IFF | aucune / RLE | 65 536 x 65 536 | supérieur à 16 777 216 |
| JPEG | JPEG | 65 536 x 65 536 | supérieur à 16 777 216 |
| PCX | aucune / RLE | 65 536 x 65 536 | 16 777 216 |
| PNG | RLE | 65 536 x 65 536 | supérieur à 16 777 216 |
| TGA | aucune / RLE | 65 536 x 65 536 | supérieur à 16 777 216 |
| TIFF/TIF | Packbits / CCITT G3&4 / RLE / JPEG / LZW / UIT-T |
232-1 | supérieur à 16 777 216 |
Le format BMP
Le format BMP est un des formats les plus simples développé conjointement par Microsoft et IBM, ce qui explique qu'il soit particulièrement répandu sur les plates formes Windows et OS/2. Un fichier BMP est un fichier bitmap, c'est-à-dire un fichier d'image graphique stockant les pixels sous forme de tableau de points et gérant les couleurs soit en couleur vraie soit grâce à une palette indexée. Le format BMP a été étudié de telle manière à obtenir un bitmap indépendant du périphérique d'affichage (DIB, Device independent bitmap).
La structure d'un fichier bitmap est la suivante :
- En-tête du fichier (en anglais file header)
- En-tête du bitmap (en anglais bitmap information header, appelé aussi information Header)
- Palette (optionnellement)
- Corps de l'image
En-tête du fichier
L'entête du fichier fournit des informations sur le type de fichier (Bitmap), sa taille et indique où commencent les informations concernant l'image à proprement parler.
L'entête est composé de quatre champs :
- La signature (sur 2 octets), indiquant qu'il s'agit d'un fichier BMP à l'aide des deux caractères.
- BM, 424D en hexadécimal, indique qu'il s'agit d'un Bitmap Windows.
- BA indique qu'il s'agit d'un Bitmap OS/2.
- CI indique qu'il s'agit d'une icone couleur OS/2.
- CP indique qu'il s'agit d'un pointeur de couleur OS/2.
- IC indique qu'il s'agit d'une icone OS/2.
- PT indique qu'il s'agit d'un pointeur OS/2.
- La taille totale du fichier en octets (codée sur 4 octets)
- Un champ réservé (sur 4 octets)
- L'offset de l'image (sur 4 octets), en français décalage, c'est-à-dire l'adresse relative du début des informations concernant l'image par rapport au début du fichier
En-tête de l'image
L'entête de l'image fournit des informations sur l'image, notamment ses dimensions et ses couleurs.
L'entête de l'image est composé de quatre champs :
- La taille de l'entête de l'image en octets (codée sur 4 octets). Les valeurs hexadécimales suivantes sont possibles suivant le type de format BMP :
- 28 pour Windows 3.1x, 95, NT, ...
- 0C pour OS/2 1.x
- F0 pour OS/2 2.x
- La largeur de l'image (sur 4 octets), c'est-à-dire le nombre de pixels horizontalement (en anglais width)
- La hauteur de l'image (sur 4 octets), c'est-à-dire le nombre de pixels verticalement (en anglais height)
- Le nombre de plans (sur 2 octets). Cette valeur vaut toujours 1
- La profondeur de codage de la couleur(sur 2 octets), c'est-à-dire le nombre de bits utilisés pour coder la couleur. Cette valeur peut-être égale à 1, 4, 8, 16, 24 ou 32
- La méthode de compression (sur 4 octets). Cette valeur vaut 0 lorsque l'image n'est pas compressée, ou bien 1, 2 ou 3 suivant le type de compression utilisé :
- 1 pour un codage RLE de 8 bits par pixel
- 2 pour un codage RLE de 4 bits par pixel
- 3 pour un codage bitfields, signifiant que la couleur est codé par un triple masque représenté par la palette
- La taille totale de l'image en octets (sur 4 octets).
- La résolution horizontale (sur 4 octets), c'est-à-dire le nombre de pixels par mètre horizontalement
- La résolution verticale (sur 4 octets), c'est-à-dire le nombre de pixels par mètre verticalement
- Le nombre de couleurs de la palette (sur 4 octets)
- Le nombre de couleurs importantes de la palette (sur 4 octets). Ce champ peut être égal à 0 lorsque chaque couleur a son importance.
Palette de l'image
La palette est optionnelle. Lorsqu'une palette est définie, elle contient successivement 4 octets pour chacune de ses entrées représentant :
- La composante bleue (sur un octet)
- La composante verte (sur un octet)
- La composante rouge (sur un octet)
- Un champ réservé (sur un octet)
Codage de l'image
Le codage de l'image se fait en écrivant successivement les bits correspondant à chaque pixel, ligne par ligne en commençant par le pixel en bas à gauche.
- Les images en 2 couleurs utilisent 1 bit par pixel, ce qui signifie qu'un octet permet de coder 8 pixels
- Les images en 16 couleurs utilisent 4 bits par pixel, ce qui signifie qu'un octet permet de coder 2 pixels
- Les images en 256 couleurs utilisent 8 bits par pixel, ce qui signifie qu'un octet code chaque pixel
- Les images en couleurs réelles utilisent 24 bits par pixel, ce qui signifie qu'il faut 3 octets pour coder chaque pixel, en prenant soin de respecter l'ordre de l'alternance bleu, vert et rouge.
Chaque ligne de l'image doit comporter un nombre total d'octets qui soit un multiple de 4; si ce n'est pas le cas, la ligne doit être complétée par des 0 de telle manière à respecter ce critère.
Le format GIF
Le format GIF (Graphic Interchange Format) est un format de fichier graphique bitmap (raster) par la société Compuserve.
Il existe deux versions de ce format de fichier développées respectivement en 1987 et 1989 :
- GIF 87a supportant la compression LZW, l'entrelacement (permettant un affichage progressif), une palette de 256 couleurs et la possibilité d'avoir des images animées (appelées GIFs animés) en stockant plusieurs images au sein du même fichier.
- GIF 89a ajoutant la possibilité de définir une couleur transparente dans la palette et de préciser le délai pour les animations.
Caractéristiques du format GIF
Une image GIF peut contenir de 2 à 256 couleurs (2, 4, 8, 16, 32, 64, 128 ou 256) parmi 16.8 millions dans sa palette. Ainsi grâce à cette palette limitée en nombre de couleurs (et non limité en couleurs différentes), les images obtenues par ce format ont une taille généralement très faible.
Toutefois, étant donné le caractère propriétaire de l'algorithme de compression LZW, tous les éditeurs de logiciel manipulant des images GIF doivent payer une redevance à la société détentrice des droits, Unisys. C'est une des raisons pour lesquelles le format PNG est de plus en plus plébiscité, au détriment du format GIF.
Plus d'informations
Le format PCX
Le format PCX a été mis au point par la société ZSoft, éditant le logiciel PaintBrush équipant en standard les systèmes d'exploitation Microsoft Windows à partir des années 80.
Le format PCX est un format bitmap permettant d'encoder des images dont la dimension peut aller jusqu'à 65536 par 65536 et codées sur 1 bit, 4 bit, 8 bit ou 24 bit (correspondant respectivement à 2, 16, 256 ou 16 millions de couleurs).
La structure d'un fichier PCX est la suivante :
- En-tête de l'image (en anglais bitmap information header) d'une longueur de 128 octets
- Corps de l'image
- Informations
- Palette des couleurs (optionnelle). Il s'agit d'un champ de 768 octets permettant de stocker les différentes valeurs de rouge, de vert et de bleu (RVB) de chaque élément de la palette
En-tête de l'image
L'entête de l'image fournit des informations sur l'image, notamment ses dimensions et ses couleurs.
L'entête de l'image est composé des champs suivants :
- La signature du fichier (sur un octet), permettant d'identifier le type du fichier. La valeur hexadécimale 0A désigne un fichier PCX.
- La version (sur un octet) :
- 0= Version 2.5
- 2= Version 2.8 avec palette
- 3= Version 2.8 sans palette
- 5= Version 3.0
- Le format (sur un octet), c'est-à-dire la méthode d'encodage utilisée. La valeur 1 désigne un encodage RLE.
- Le nombre de bits par pixel par plan (sur un octet)
- Xmin (sur deux octets), abscisse de l'angle supérieur gauche
- Ymin (sur deux octets), ordonnée de l'angle supérieur gauche
- Xmax (sur deux octets), abscisse de l'angle inférieur droit
- Ymax (sur deux octets), ordonnée de l'angle inférieur droit
- résolution horizontale (sur deux octets)
- résolution verticale (sur deux octets)
- Palette (sur 48 octets)
- Réservé (sur un octet)
- Nombre de plans de couleur (sur un octet)
- Nombre de bits par ligne (sur 2 octets)
- Type de palette (sur 2 octets)
- Remplissage (58 octets)
Il est intéressant de noter que «Xmax - Xmin + 1» représente la largeur de l'image et que «Ymax - Ymin + 1» représente la hauteur de celle-ci.
Codage de l'image
Le codage de l'image se fait en écrivant successivement les bits correspondant à chaque pixel, ligne par ligne en commençant par le pixel en haut à gauche, puis en parcourant de gauche à droite et de haut en bas.
Le format PNG
Le format PNG (Portable Network Graphics, ou format Ping) est un format de fichier graphique bitmap (raster). Il a été mis au point en 1995 afin de fournir une alternative libre au format GIF, format propriétaire dont les droits sont détenus par la société Unisys (propriétaire de l'algorithme de compression LZW), ce qui oblige chaque éditeur de logiciel manipulant ce type de format à leur verser des royalties. Ainsi PNG est également un acronyme récursif pour PNG's Not Gif.
Caractéristiques du format PNG
Le format PNG permet de stocker des images en noir et blanc (jusqu'à 16 bits par pixels de profondeur de codage), en couleurs réelles (True color, jusqu'à 48 bits par pixels de profondeur de codage) ainsi que des images indexées, faisant usage d'une palette de 256 couleurs.
De plus il supporte la transparence par couche alpha, c'est-à-dire la possibilité de définir 256 niveaux de transparence, tandis que le format GIF ne permet de définir qu'une seule couleur de la palette comme transparente. Il possède également une fonction d'entrelacement permettant d'afficher l'image progressivement.
La compression proposé par ce format est une compression sans perte (lossless compression) 5 à 25% meilleure que la compression GIF.
Enfin PNG embarque des informations sur le gamma de l'image, ce qui rend possible une correction gamma et permet une indépendance vis-à-vis des périphériques d'affichage. Des mécanismes de correction d'erreurs sont également embarquées dans le fichier afin de garantir son intégrité.
Structure d'un fichier PNG
Un fichier PNG est constité d'une signature, permettant de signaler qu'il s'agit d'un fichier PNG, puis d'une série d'éléments appelés chunks (le terme "segments" sera utilisé par la suite). La signature d'un fichier PNG (en notation décimale) est la suivante :
137 80 78 71 13 10 26 10
La même signature en notation hexadécimale est :
89 50 4E 47 0D 0A 1A 0A
Chaque segment (chunk) est composé de 4 parties :
- La taille, un entier non signé de 4 octets, décrivant la taille du segment
- Le type de segment (chunk type) : un code de 4 caractères (4 octets) composés de caractères ASCII alphanumériques (A-Z, a-z, 65 à 90 et 97 à 122) permettant de qualifier la nature du segment
- Les données du segment (chunk data)
- Le CRC (cyclic redundancy check), un code correcteur de 4 octets permettant de vérifier l'intégrité du segment
Les segments peuvent être présents dans n'importe quel ordre si ce n'est qu'ils doivent commencer par le segment d'en-tête (IHDR chunk) et finir par le segment de fin (IEND chunk)
Les principaux segments (appelés critical chunks) sont :
- IHDR Image header
- PLTE Palette
- IDAT Image data
- IEND Image trailer
Les autres segments (appelés anciliary chunks) sont les suivants :
- bKGD Background color
- cHRM Primary chromaticities and white point
- gAMA Image gamma
- hIST Image histogram
- pHYs Physical pixel dimensions
- sBIT Significant bits
- tEXt Textual data
- tIME Image last-modification time
- tRNS Transparency
- zTXt Compressed textual data
Plus d'informations
Le format TIF
Le format TIF ou TIFF (Tagged Image File Format) est un format de fichier graphique bitmap (raster). Il a été mis au point en 1987 par la société Aldus (appartenant désormais à Adobe). Les dernières spécifications (Revision 6.0) ont été publiées en 1992.
Caractéristiques du format TIF
Le format TIFF est un ancien format graphique, permettant de stocker des images bitmap (raster) de taille importante (plus de 4 Go compressées), sans perdition de qualité et indépendamment des plates formes ou des périphériques utilisés (Device-Independant Bitmap, noté DIB).
Le format TIFF permet de stocker des images en noir et blanc, en couleurs réelles (True color, jusqu'à 32 bits par pixels) ainsi que des images indexées, faisant usage d'une palette de couleurs.
De plus le format TIF permet l'usage de plusieurs espaces de couleurs :
- RGB
- CMYK
- CIE L*a*b
- YUV / YCrCb
Structure d'un fichier TIF
Le principe du format TIF consiste à définir des balises (en anglais tags, d'où le nom Tagged Image File Format) décrivant les caractéristiques de l'image.
Les balises permettent de stocker des informations concernant aussi bien les dimensions de l'image, le nombre de couleurs utilisées, le type de compression (de nombreux algorithmes peuvent ainsi être utilisés Packbits / CCITT G3&4 / RLE / JPEG / LZW / UIT-T), ou bien la correction gamma.
Ainsi la description de l'image par balise rend simple la programmation d'un logiciel permettant d'enregistrer au format TIFF. En contrepartie la multiplicité des options proposées est telle que nombre de lecteurs d'images supportant le format TIFF ne les intègrent pas toutes, si bien qu'il arrive qu'une image enregistrée au format TIFF ne soit pas lisible sous un autre.
Plus d'informations
La compression des données
Pourquoi compresser les données ?
De nos jours, la puissance des processeurs augmente plus vite que les capacités de stockage, et énormément plus vite que la bande passante des réseaux, car cela demande d'énormes changements dans les infrastructures de télécommunication.
Ainsi, pour pallier ce manque, il est courant de réduire la taille des données en exploitant la puissance des processeurs plutôt qu'en augmentant les capacités de stockage et de transmission des données.
Qu'est-ce que la compression des données ?
La compression consiste à réduire la taille physique de blocs d'informations. Un compresseur utilise un algorithme qui sert à optimiser les données en utilisant des considérations propres au type de données à compresser; un décompresseur est donc nécessaire pour reconstruire les données originelles grâce à l'algorithme inverse de celui utilisé pour la compression.
La méthode de compression dépend intrinsèquement du type de données à compresser : on ne compressera pas de la même façon une image qu'un fichier audio...
Caractéristiques de la compression
La compression peut se définir par le quotient de compression, c'est-à-dire le quotient du nombre de bits dans l'image compressée par le nombre de bits dans l'image originale.
Le taux de compression, souvent utilisé, est l'inverse du quotient de compression, il est habituellement exprimé en pourcentage.
Enfin le gain de compression, également exprimé en pourcentage, est le complément à 1 du taux de compression :
Types de compression et méthodes
Compression physique et logique
La compression physique agit directement sur les données; il s'agit ainsi de regarder les données redondantes d'un train de bits à un autre.
La compression logique par contre est effectuée par un raisonnement logique en substituant une information par une information équivalente.
Compression symétrique et asymétrique
Dans le cas de la compression symétrique, la même méthode est utilisée pour compresser et décompresser l'information, il faut donc la même quantité de travail pour chacune de ces opérations. C'est ce type de compression qui est généralement utilisée dans les transmissions de données.
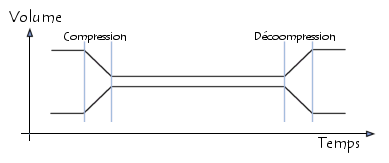
La compression asymétrique demande plus de travail pour l'une des deux opérations, on recherche souvent des algorithmes pour lesquels la compression est plus lente que la décompression. Des algorithmes plus rapides en compression qu'en décompression peuvent être nécessaire lorsque l'on archive des données auxquelles on n'accède peu souvent (pour des raisons de sécurité par exemple), car cela crée des fichiers compacts.
Compression avec pertes
La compression avec pertes (en anglais lossy compression), par opposition à la compression sans pertes (lossless compression), se permet d'éliminer quelques informations pour avoir le meilleur taux de compression possible, tout en gardant un résultat qui soit le plus proche possible des données originales. C'est le cas par exemple de certaines compressions d'images ou de sons.
Etant donné que ce type de compression supprime des informations contenues dans les données à compresser, on parle généralement de méthodes de compression irréversibles. Les fichiers exécutables par exemple ont notamment besoin de conserver leur intégrité pour fonctionner, en effet il n'est pas concevable de reconstruire à l'à-peu-près un programme en omettant parfois des bits et en en ajoutant là oû il n'en faut pas.
Encodage adaptif, semi adaptif et non adaptif
Certains algorithmes de compression sont basés sur des dictionnaires spécifiques à un type de données : ce sont des encodeurs non adaptifs. Les occurrences de lettres dans un fichier texte par exemple dépendent de la langue dans laquelle celui-ci est écrit.
Un encodeur adaptif s'adapte aux données qu'il va devoir compresser, il ne part pas avec un dictionnaire déjà préparé pour un type de données.
Enfin un encodeur semi-adaptif construira celui-ci en fonction des données à compresser : il construit le dictionnaire en parcourant le fichier, puis compresse ce dernier.
La compression des images numériques
La concaténation des points
La concaténation de point est une méthode permettant de stocker les points d'une manière optimale: pour une image monochrome il n'y a, par définition, que deux couleurs, un point de l'image peut donc être codé sur un seul bit pour gagner de l'espace mémoire.
La compression RLE
La méthode de compression RLE (Run Length Encoding, parfois notée RLC pour Run Length Coding) est utilisée par de nombreux formats d'images (BMP, PCX, TIFF). Elle est basée sur la répétition d'éléments consécutifs.
Le principe de base consiste à coder un premier élément donnant le nombre de répétitions d'une valeur puis le compléter par la valeur à répéter. Ainsi selon ce principe la chaîne "AAAAAHHHHHHHHHHHHHH" compressée donne "5A14H". Le gain de compression est ainsi de (19-5)/19 soit environ 73,7%. En contrepartie pour la chaîne "REELLEMENT", dans lequel la redondance des caractères est faible, le résultat de la compression donne "1R2E2L1E1M1E1N1T"; la compression s'avère ici très coûteuse, avec un gain négatif valant (10-16)/10 soit -60%!
En réalité la compression RLE est régie par des règles particulières permettant de compresser lorsque cela est nécessaire et de laisser la chaîne telle quelle lorsque la compression induit un gaspillage. Ces règles sont les suivantes :
- Lorsque trois éléments ou plus se répètent consécutivement alors la méthode de compression RLE est utilisée
- Sinon un caractère de contrôle (00) est inséré, suivi du nombre d'éléments de la chaîne non compressée puis de cette dernière
- Si le nombre d'éléments de la chaîne est impair, le caractère de contrôle (00) est ajouté à la fin
- Enfin des caractères de contrôles spécifiques ont été définis afin de coder :
- une fin de ligne (00 01)
- la fin de l'image (00 00)
- un déplacement du pointeur dans l'image de XX colonnes et de YY lignes dans le sens de la lecture (00 02 XX YY).
Ainsi la compression RLE n'a du sens que pour les données possédant de nombreux éléments consécutifs redondants, notamment les images possédant de large parties uniformes. Cette méthode a toutefois l'avantage d'être peu difficile à mettre en oeuvre. Il existe des variantes dans lesquelles l'image est encodée par pavés de points, selon des lignes, ou bien même en zigzag.
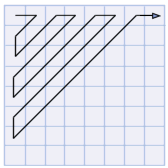
Le codage de Huffman
David Huffman a proposé en 1952 une méthode statistique qui permet d'attribuer un mot de code binaire aux différents symboles à compresser (pixels ou caractères par exemple). La longueur de chaque mot de code n'est pas identique pour tous les symboles: les symboles les plus fréquents (qui apparaissent le plus souvent) sont codés avec de petits mots de code, tandis que les symboles les plus rares reçoivent de plus longs codes binaires. On parle de codage à longueur variable (en anglais VLC pour variable code length) préfixé pour désigner ce type de codage car aucun code n'est le préfixe d'un autre. Ainsi la suite finale de mots codés à longueurs variables sera en moyenne plus petite qu'avec un codage de taille constante.
Le codeur de Huffman crée un arbre ordonné à partir de tous les symboles et de leur fréquence d'apparition. Les branches sont construites récursivement en partant des symboles les moins fréquents. La construction de l'arbre se fait en ordonnant dans un premier temps les symboles par fréquence d'apparition. successivement les deux symboles de plus faible fréquence d'apparition sont retirés de la liste et rattachés à un noeud dont le poids vaut la somme des fréquences des deux symboles. Le symbole de plus faible poids est affecté à la branche 1, l'autre à la branche 0 et ainsi de suite en considérant chaque noeud formé comme un nouveau symbole, jusqu'à obtenir un seul noeud parent appelé racine.
Le code de chaque chaque symbole correspond à la suite des codes le long du chemin allant de ce caractère à la racine. Ainsi, plus le symbole est "profond" dans l'arbre, plus le mot de code sera long.
Soit la phrase suivante : "COMMENT_CA_MARCHE". Voici les fréquences d'apparitions des lettres
| M | A | C | E | _ | H | O | N | T | R |
| 3 | 2 | 2 | 2 | 2 | 1 | 1 | 1 | 1 | 1 |
Voici l'arbre correspondant :
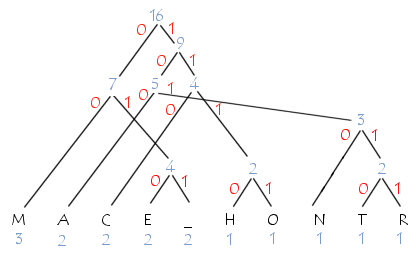
Les codes correspondants à chaque caractère sont tels que les codes des caractères les plus fréquents sont courts et ceux correspondant aux symboles les moins fréquents sont longs :
| M | A | C | E | _ | H | O | N | T | R |
| 00 | 100 | 110 | 010 | 011 | 1110 | 1111 | 1010 | 10110 | 10111 |
Les compressions basées sur ce type de codage donnent de bons taux de compressions, en particulier pour les images monochromes (les fax par exemple). Il est notamment utilisé dans les recommandations T4 et T5 de l'ITU-T
La compression LZW
Abraham Lempel et Jakob Ziv sont les créateurs du compresseur LZ77, inventé en 1977 (d'où son nom). Ce compresseur était alors utilisé pour l'archivage (les formats ZIP, ARJ et LHA l'utilisent).
En 1978 ils créent le compresseur LZ78 spécialisé dans la compression d'images (ou tout type de fichier de type binaire).
En 1984, Terry Welch de la société Unisys le modifia pour l'utiliser dans des contrôleurs de disques durs, son initiale vint donc se rajouter à l'abréviation LZ pour donner LZW.
LZW est un algorithme très rapide aussi bien en compression qu'en décompression, basé sur la multiplicité des occurences de séquences de caractères dans la chaîne à encoder. Son principe consiste à substituer des motifs par un code d'affectation (indice) en construisant au fur et à mesure un dictionnaire. De plus, il travaille sur des bits et non sur des octets, il ne dépend donc pas de la manière de laquelle le processeur code les informations. C'est un des algorithmes les plus populaires, il est notamment utilisé dans les formats TIFF et GIF. La méthode de compression LZW ayant été brevetée par la société Unisys, c'est l'algorithme LZ77, libre de droit, qui est utilisé dans les images PNG.
Construction du dictionnaire
Le dictionnaire est initialisé avec les 256 valeurs de la table ASCII. Le fichier à compresser est découpé en chaînes d'octets (ainsi pour des images monochromes - codées sur 1 bit - cette compression est peu efficace), chacune de ces chaînes est comparée au dictionnaire et est ajoutée si jamais elle n'y est pas présente.
La compression
L'algorithme parcourt le flot d'informations en le codant; si jamais une chaîne est plus petite que le plus grand mot du dictionnaire alors elle est transmise.
La décompression
Lors de la décompression, l'algorithme reconstruit le dictionnaire dans le sens inverse, ce dernier n'a donc pas besoin d'être stocké.
La compression JPG
L'acronyme JPEG (Joint Photographic Expert Group prononcez jipègue ou en anglais djaypègue) provient de la réunion en 1982 d'un groupe d'experts de la photographie, dont le principal souci était de travailler sur les façons de transmettre des informations (images fixes ou animées). En 1986, l'ITU-T mit au point des méthodes de compression destinées à l'envoi de fax. Ces deux groupes se rassemblèrent pour créer un comité conjoint d'experts de la photographie (JPEG).
Contrairement à la compression LZW, la compression JPEG est une compression avec pertes, ce qui lui permet, en dépit d'une perte de qualité, un des meilleurs taux de compression (20:1 à 25:1 sans perte notable de qualité).
Cette méthode de compression est beaucoup plus efficace sur les images photographiques (comportant de nombreux pixels de couleurs différentes) et non sur des images géométriques (à la différence de la compression LZW) car sur ces dernières les différences de nuances dûes à la compression sont très visibles.
Les étapes de la compression JPEG sont les suivantes :
- Rééchantillonnage de la chrominance, car l'oeil ne peut discerner de différences de chrominance au sein d'un carré de 2x2 points
- Découpage de l'image en blocs de 8x8 points, puis l'application de la fonction DCT (Discrete Cosinus Transform, transformation discrète en cosinus) qui décompose l'image en somme de fréquences
- Quantification de chaque bloc, c'est-à-dire qu'il applique un coefficient de perte (qui permet de déterminer le ratio taille/qualité) "annulera" ou diminuera des valeurs de hautes fréquences, afin d'atténuer les détails en parcourant le bloc intelligemment avec un codage RLE (en zig-zag pour enlever un maximum de valeurs nulles).
- Encodage de l'image puis compression avec la méthode d'Huffman
Le format de fichier embarquant un flux codé en JPEG est en réalité appelés JFIF (JPEG File Interchange Format, soit en français Format d'échange de fichiers JPEG), mais par déformation le terme de "fichier JPEG" est couramment utilisé.
Il est à noter qu'il existe une forme de codage JPEG sans perte (appelé lossless). Bien que peu utilisé par la communauté informatique en général, il sert surtout pour la transmission d'images médicales pour éviter de confondre des artefacts (purement liés à l'image et à sa numérisation) avec de réels signes pathologiques. La compression est alors beaucoup moins efficace (facteur 2 seulement).
Traitement d'images
Introduction au traitement d'images
On désigne par traitement d'images numériques l'ensemble des techniques permettant de modifier une image numérique dans le but de l'améliorer ou d'en extraire des informations.
Histogramme
Un histogramme est un graphique statistique permettant de représenter la distribution des intensités des pixels d'une image, c'est-à-dire le nombre de pixels pour chaque intensité lumineuse. Par convention un histogramme représente le niveau d'intensité en abscisse en allant du plus foncé (à gauche) au plus clair (à droite).
Ainsi, l'histogramme d'une image en 256 niveaux de gris sera représenté par un graphique possédant 256 valeurs en abscisses, et le nombre de pixels de l'image en ordonnées. Prenons par exemple l'image suivante composée de niveaux de gris:

L'histogramme et la palette associés à cette image sont respectivement les suivants :
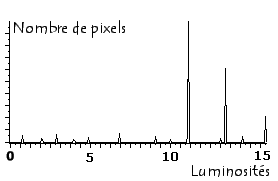
![]()
L'histogramme fait apparaître que les tons gris clairs sont beaucoup plus présents dans l'image que les tons foncés.
Le ton de gris le plus utilisé est le 11ème en partant de la gauche.
Pour les images en couleur plusieurs histogrammes sont nécessaires. Par exemple pour une image codée en RGB :
- un histogramme représentant la distribution de la luminance,
- trois histogrammes représentant respectivement la distribution des valeurs respectives des composantes rouges, bleues et vertes.
Histogramme cumulé
L'histogramme cumulé représente la distribution cumulé des intensités des pixels d'une image, c'est-à-dire le nombre de pixels ayant au moins une intensité lumineuse donnée.
Modification de l'histogramme
L'histogramme est un outil très utile pour étudier la répartition des composantes d'une image mais il permet également de corriger le contraste et l'échelle des couleurs pour des images sur-exposées ou sous-exposées. En outre sa modification n'altère pas les informations contenues dans l'image mais les rend plus ou moins visibles.
La modification d'un histogramme est généralement représentée sur une courbe (appelée courbe tonale) indiquant la modification globale des composantes de l'image avec en abscisse les valeurs initiales et en ordonnées les valeurs après modification. La courbe tonale correspond à une fonction de transfert définie par une table de transcodage appelé look up table, notée LUT. Ainsi la diagonale indique la courbe telle que les valeurs initiales sont égales aux valeurs finales, c'est-à-dire lorsque aucune modification n'a eu lieu. Les valeurs à gauche de la valeur moyenne sur l'axe des abscisses représentent les pixels "clairs" tandis que ceux à droite représentent les pixels foncés.
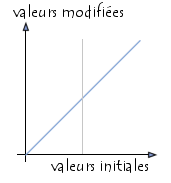
Ainsi, si la courbe de modification de l'histogramme est située en dessous de la diagonale, les pixels auront des valeurs plus faibles et seront donc éclaircis. A l'inverse si la courbe est au dessus de la diagonale, les pixels seront assombris.
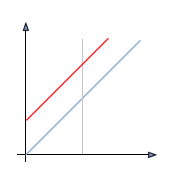 |
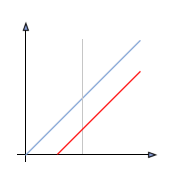 |
| Eclaircissement | Assombrissement |
Egalisation de l'histogramme
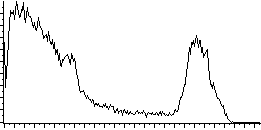
L'égalisation d'histogramme a pour but d'harmoniser la répartition des niveaux de luminosité de l'image, de telle manière à tendre vers un même nombre de pixel pour chacun des niveaux de l'histogramme. Cette opération vise à augmenter les nuances dans l'image.
 |
 |
 |
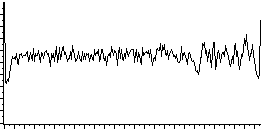 |
La courbe tonale correspondant à l'égalisation de l'histogramme dépend totalement de l'image. Toutefois la plupart des outils proposent généralement un outil permettant de faire cette opération automatiquement.
Etirement de l'histogramme
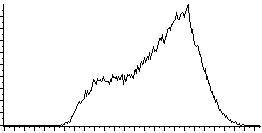
L'étirement d'histogramme (aussi appelé "linéarisation d'histogramme" ou "expansion de la dynamique") consiste à répartir les fréquences d'apparition des pixels sur la largeur de l'histogramme. Ainsi il s'agit d'une opération consistant à modifier l'histogramme de telle manière à répartir au mieux les intensités sur l'échelle des valeurs disponibles. Ceci revient à étendre l'histogramme afin que la valeur d'intensité la plus faible soit à zéro et que la plus haute soit à la valeur maximale.
De cette façon, si les valeurs de l'histogramme sont très proches les unes des autres, l'étirement va permettre de fournir une meilleure répartition afin de rendre les pixels clairs encore plus clairs et les pixels foncés proches du noir.
 |
 |
 |
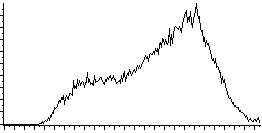 |
Il est ainsi possible d'augmenter le contraste d'une image. Par exemple une image trop foncée pourra devenir plus "visible". Toutefois cela ne donne pas toujours de bons résultats...
La courbe tonale correspondant à un étalement de l'histogramme est de la forme suivante :
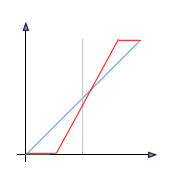
Seuillage
L'opération dite de "seuillage simple" consiste à mettre à zéro tous les pixels ayant un niveau de gris inférieur à une certaine valeur (appelée seuil, en anglais treshold) et à la valeur maximale les pixels ayant une valeur supérieure. Ainsi le résultat du seuillage est une image binaire contenant des pixels noirs et blancs, c'est la raison pour laquelle le terme de binarisation est parfois employé. Le seuillage permet de mettre en évidence des formes ou des objets dans une image. Toutefois la difficulté réside dans le choix du seuil à adopter.
Voici une image en 256 niveaux de gris et les résultat d'une opération de seuillage avec les valeurs respectives de seuil de 125 et 200 :

 |
 |
La courbe tonale de l'opération de seuillage est la suivante :
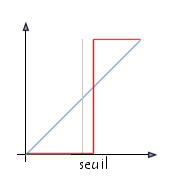
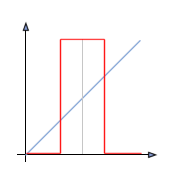
Par opposition au "seuillage simple" il est possible de définir deux valeurs de seuil, respectivement borne inférieure et borne supérieure, afin de mettre à la valeur maximale les pixels ayant une valeur comprise entre les bornes et à zéro l'ensemble des autres valeurs :
Inversion
L'opération d'inversion consiste, comme son nom l'indique, à inverser les valeurs des pixels par rapport à la moyenne des valeurs possibles. Le résultat obtenu est appelé négatif.
 |
 |
La courbe tonale de l'opération d'inversion vidéo est la suivante :
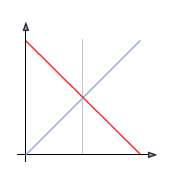
Les filtres de traitement d'images
Filtrage
Le filtrage consiste à appliquer une transformation (appelée filtre) à tout ou partie d'une image numérique en appliquant un opérateur. On distingue généralement les types de filtres suivants :
- les filtres passe-bas, consistant à atténuer les composantes de l'image ayant une fréquence haute (pixels foncés). Ce type de filtrage est généralement utilisé pour atténuer le bruit de l'image, c'est la raison pour laquelle on parle habituellement de lissage. Les filtres moyenneurs sont un type de filtres passe-bas dont le principe est de faire la moyenne des valeurs des pixels avoisinants. Le résultat de ce filtre est une image plus floue.
- les filtres passe-haut, à l'inverse des passe-bas, atténuent les composantes de basse fréquence de l'image et permettent notamment d'accentuer les détails et le contraste, c'est la raison pour laquelle le terme de "filtre d'accentuation" est parfois utilisé.
- les filtres passe-bande permettant d'obtenir la différence entre l'image originale et celle obtenue par application d'un filtre passe-bas.
- les filtres directionnels appliquant une transformation selon une direction donnée.
On appelle filtrage adaptatif les opérations de filtrage possédant une étape préalable de sélection des pixels.
Qu'est-ce qu'un filtre ?
Un filtre est une transformation mathématique (appelée produit de convolution) permettant, pour chaque pixel de la zone à laquelle il s'applique, de modifier sa valeur en fonction des valeurs des pixels avoisinants, affectées de coefficients.
Le filtre est représenté par un tableau (matrice), caractérisé par ses dimensions et ses coefficients, dont le centre correspond au pixel concerné. Les coefficients du tableau déterminent les propriétés du filtre. Voici un exemple de filtre 3 x 3 :
| 1 | 1 | 1 |
| 1 | 4 | 1 |
| 1 | 1 | 1 |
Ainsi le produit de la matrice image, généralement très grande car représentant l'image initiale (tableau de pixels) par le filtre donne une matrice correspondant à l'image traitée.
Notion de bruit
Le bruit caractérise les parasites ou interférences d'un signal, c'est-à-dire les parties du signal déformées localement. Ainsi le bruit d'une image désigne les pixels de l'image dont l'intensité est très différente de celles des pixels voisins.
Le bruit peut provenir de différentes causes :
- Environnement lors de l'acquisition
- Qualité du capteur
- Qualité de l'échantillonnage
Lissage
On appelle "lissage" (parfois débruitage ou filtre anti-bruit) l'opération de filtrage visant à éliminer le bruit d'une image.
L'opération de lissage spécifique consistant à atténuer l'effet d'escalier produit par les pixels en bordure d'une forme géométrique est appelée anti-crénelage (en anglais anti-aliasing).
L'accentuation
L'accentuation (ou bruitage) est l'inverse du lissage; il s'agit d'une opération visant à accentuer les différences entre les pixels voisins.
Ainsi l'accentuation peut permettre de mettre en exergue les limites entre les zones homogènes de l'image et est alors appelée extraction de contours (également contourage ou réhaussement de contours).
Tramage
Le tramage (en anglais dithering ou halftoning) est une technique consistant à alterner des motifs géométriques utilisant peu de couleur, appelés "trame", afin de simuler une couleur plus élaborée.
En savoir plus sur ce document
Photophiles remercie Jean-François Pillou, webmaster du site Commentcamarche.net . L'auteur met à disposition selon les termes de la licence Creative Commons de nombreux articles concernant l'informatique.
Ce document intitulé "Imagerie numérique» est sous les termes de la licence Creative Commons. Vous pouvez copier, modifier des copies de cette page, dans les conditions fixées par la licence, tant que cette note apparaît clairement.